

Mekkora teljesítményt buksz az Intel (meg az AMD és az ARM) processzorok nemrég felfedezett hibája miatt? Tényleg 5-30% lesz a bukó, ahogy a gyártók tippelték? Megmértük!
Ha az elmúlt néhány napban egyáltalán nem olvastál (tech) híreket, akkor röviden update-elünk: találtak egy gigantikus hibát az Intel chipjeiben, ami az elmúlt 10 év összes inteles CPU-ját érintheti. A hiba egyik fajtája alól az AMD és az ARM sem mentes, szóval kis túlzással minden gép szarban van a világon. (Mivel hardverhiba, az oprendszer nem számít.)
Van megoldás vagy legalábbis olyasmi. A gyógyír aprócska hibája, hogy az oprendszerben egy csomó mindent nehezebben elérhetővé tesz (hogy a kernelt érintő bugot ne lehessen kihasználni), így a teljesítmény is csökkenni fog. Windows alatt a megoldás neve KB4056892, amit mindenképp érdemes telepítened, ha meglátod.
Na, de akkor mennyit is buksz emiatt az egész miatt? Lemértünk jónéhány (direkt elég eltérő teljesítményű) processzort a patch telepítése előtt és után is, hogy tisztábban lássunk!
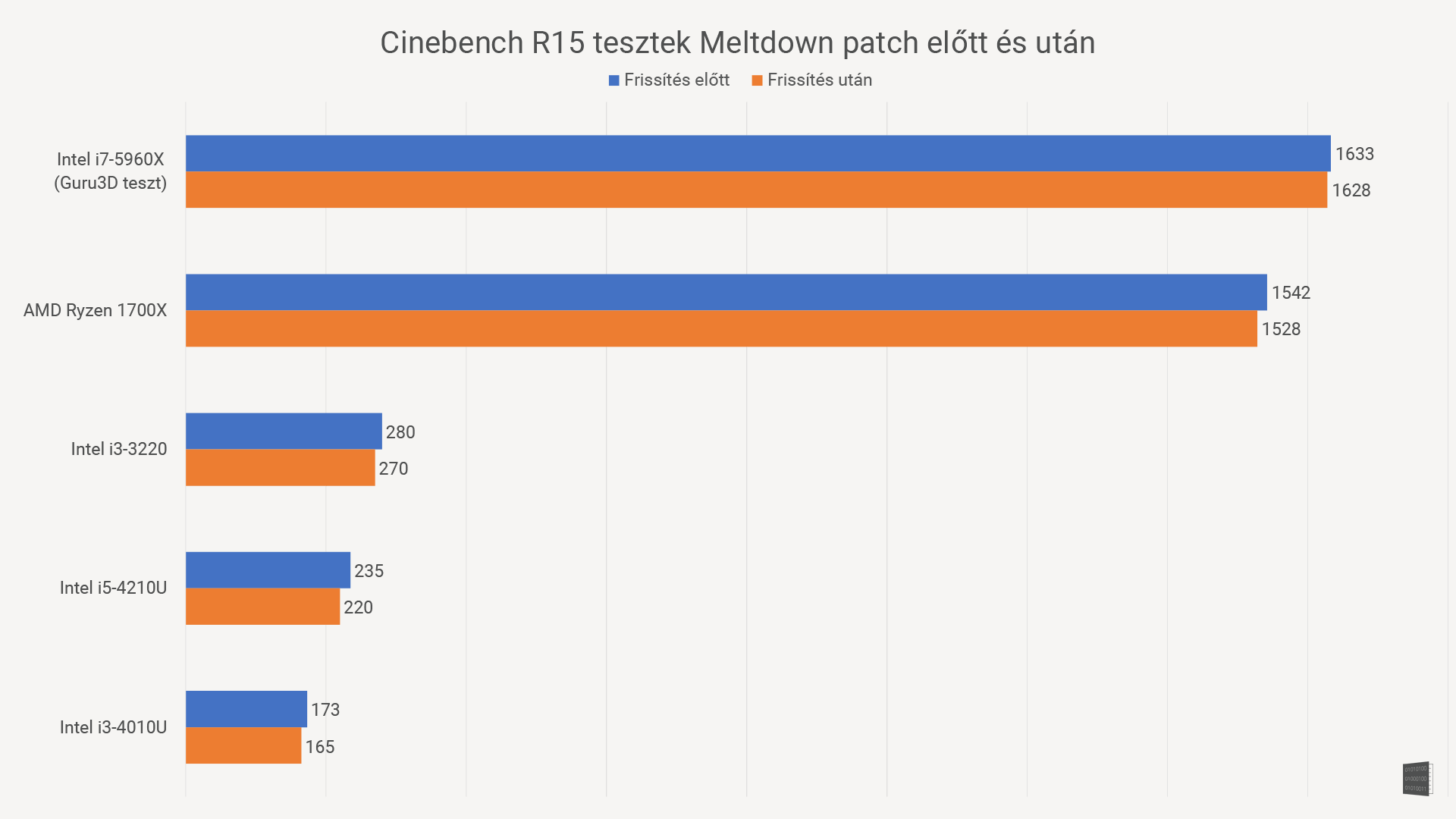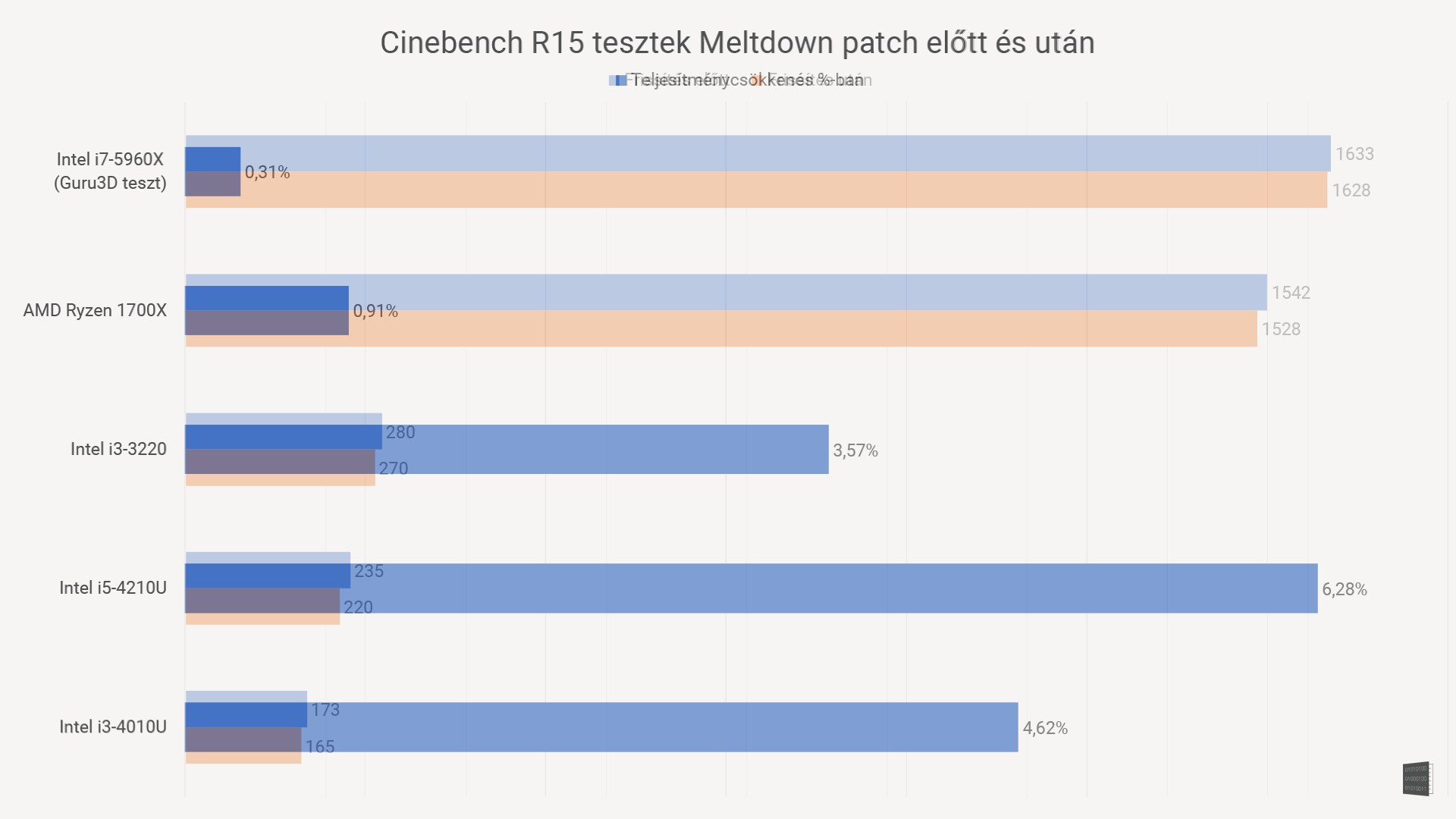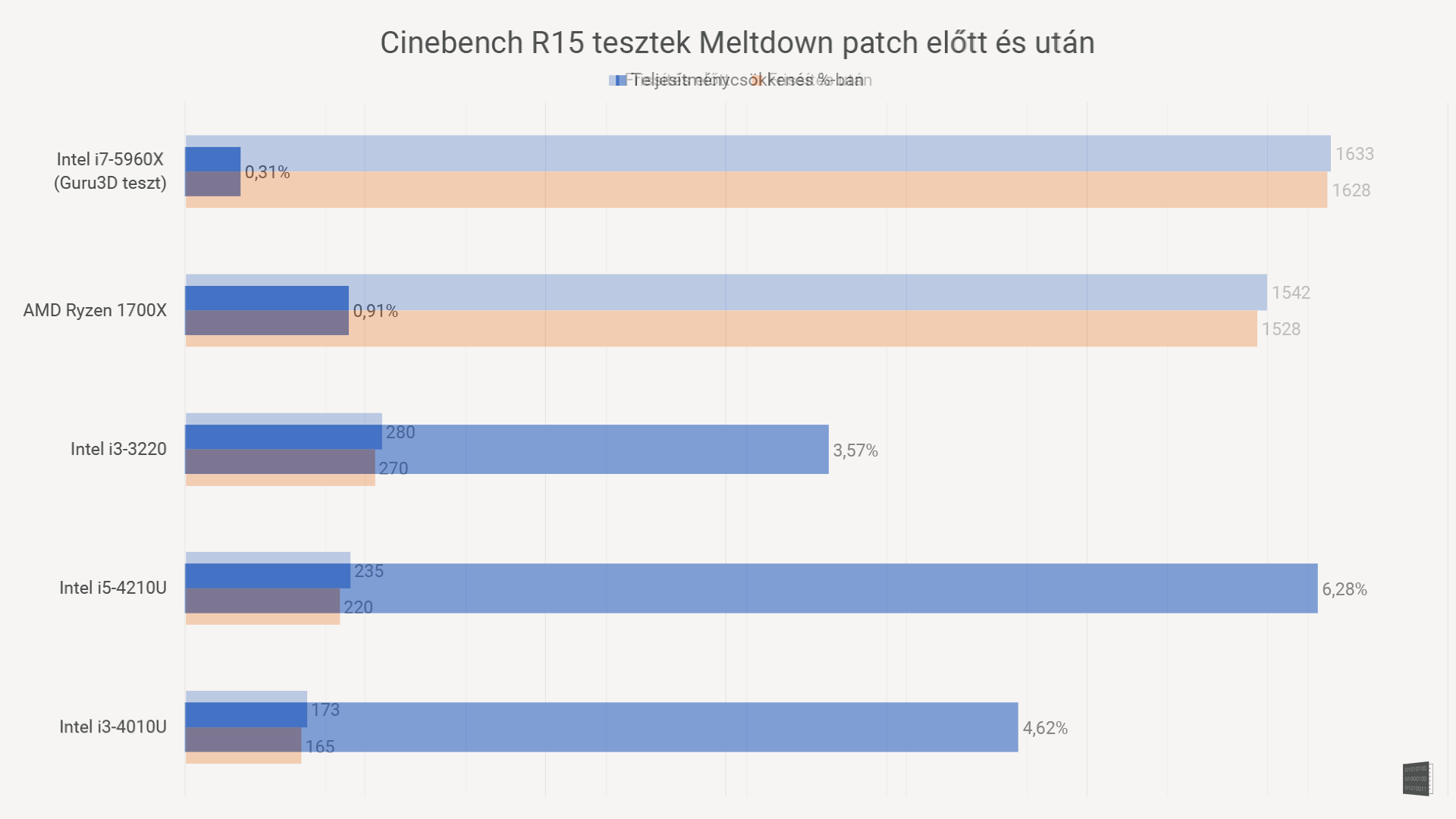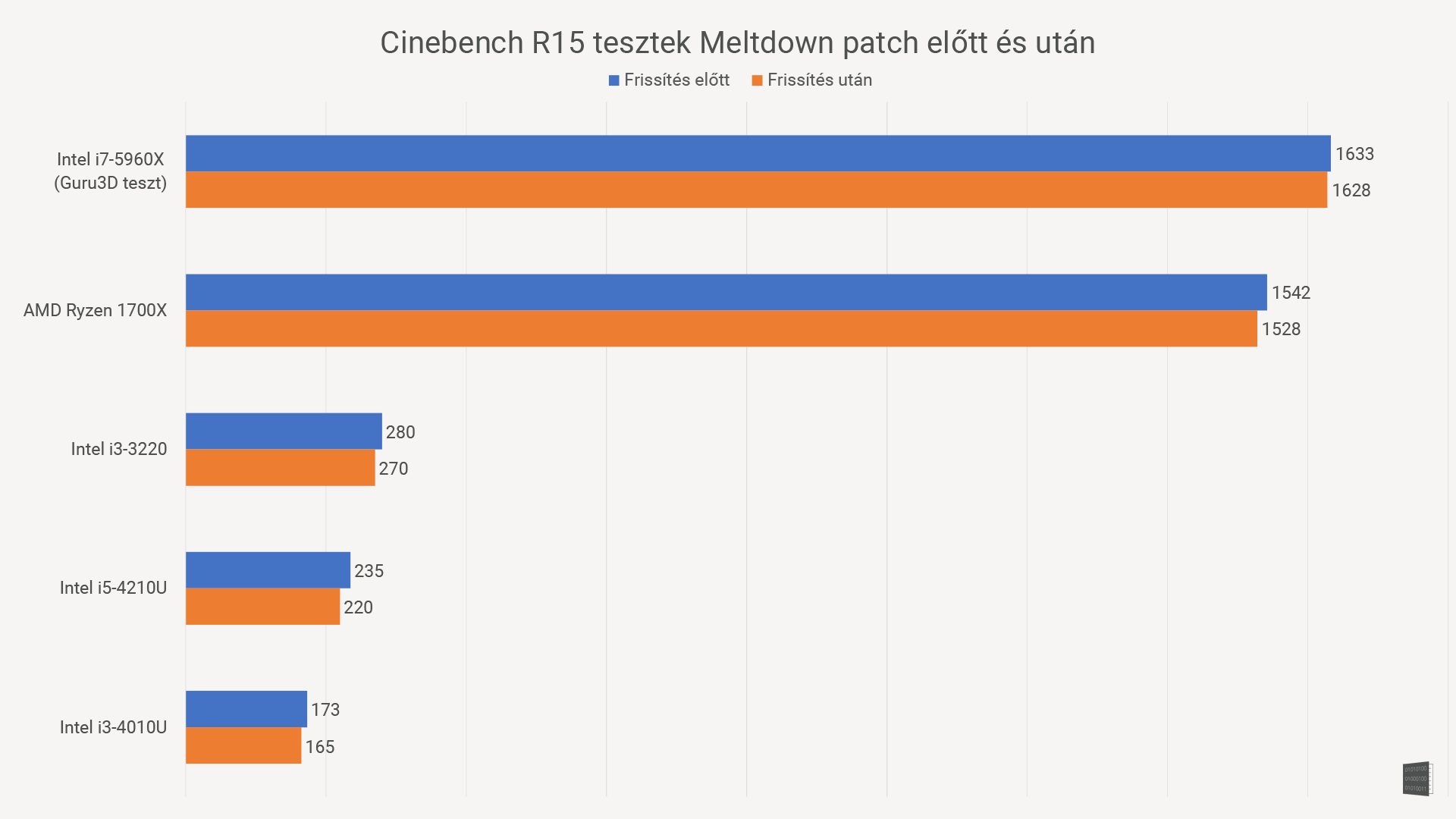
A kép 15 másodperc után vált, és százalékos különbséget mutat
Az adatok alapján úgy tűnik, hogy valóban 5% körüli csökkenésre lehet számítani majd. Ez még mindig jobb, mint a belengetett 30%, bár az is egyértelműnek tűnik, hogy az erősebb (drágább) processzorokat kevésbé viseli meg a patch, mint a gyengébb gépeket. A szomorú ebben az, hogy a gyengébb gépek, hát, eleve lassabbak, tehát rosszabb a helyzet. A másik zavaró tény, hogy az utóbbi években eléggé lelassult a generációról-generációra való teljesítménynövekedés, szóval most simán bukhatunk egy generációt teljesítményből.
Ez a teszt persze nem mutat meg mindent. Eleve túl kevés processzort teszteltünk. Ráadásul szintetikus benchmarkról van szó, ami nem minden esetben mutatja a valós eltéréseket. A várakozások szerint minél több érintett adathoz kell hozzányúlni egy feladathoz, annál jelentősebb lesz a lassulás. Ez főleg szervereknél lehet gond a várakozások szerint. Játékban ugyanakkor várhatóan nem lesz komoly a visszaesés: a tesztben is hivatkozott Guru3D tesztje minimális eltérést mutat, igaz, az általuk használt i7 5960X egy 350 ezres reaktor, és a legtöbb embernek az egész gépe nem kerül ennyibe.
Szóval itt tartunk most: nyugodtan számolhatunk azzal, hogy 5% körül lassulnak a gépeink. És sajnos minél régebbi/gyengébb a vasunk, annál nagyobb lesz a csökkenés.
![Mitől különleges a Galaxy S9 kamerája? [Videó]](https://m.blog.hu/th/thedigitalstories/image/.external/.thumbs/3736ef7b7cad7c890a2f33d2a6566c63_669ba6b3c379af695492e9efd7630b86.jpg)
![Mi az a Meltdown, és miért lassul tőle a géped? [Videó]](https://m.blog.hu/th/thedigitalstories/image/.external/.thumbs/7a0098ccfc0b917a3299101218e52750_669ba6b3c379af695492e9efd7630b86.jpg)





